Runolliset tietueet
Muokattu 4.4: Nyt julkaistuja teoksia kuvaavien ympyröiden koko määräytyy teosten lukumäärän logaritmina. Pakkautumisongelma tuntuu helpottavan ja yksityiskohdat säilyvät paremmin. Päivitin esikatselukuvan ja ladattavan PDF-tiedoston.
Jatkoin Helmet-datadumpin pyörittelyä. Istuskelin perjantai-iltapäivän työ/opiskelupaikkani järjestämässä verkostoanalyysi-metodipajassa, josta sain ajatuksen kokeilla SNA-menetelmiä Helmet-aineistoon.
Koska aineisto on melkoisen suuri -- satojatuhansia tietueita -- mopokonetta ja hermoja säästääkseni päätin ottaa aineistosta jonkin kiinnostavan osajoukon käsiteltäväkseni. Päädyin Suomessa suomeksi tai ruotsiksi julkaistuihin runoihin ja runojen kustantajiin: näin näppitultumalta runoja ei julkaista vuositasolla kovin hurjia määriä ja on mielenkiintoista tietää, mitkä tahot hoitavat tätä julkaisutoimintaa.
Aloitin tarvitsemani aineiston koostamisen ajamalla aiemmin MODS-muotoon saattamastani Helmet-datadumpista XSLT-muunnoksen CSV-taulukkomuotoon, johon tallensin kunkin runoteoksen tekijän, kustantajan ja julkaisuvuoden. XSLT-muunnoksen synnyttämät taulukot eivät olleet suoralta käsin käyttövalmiita, vaan aineistoa joutui siivoilemaan jonkin verran käsin.
Tämän jälkeen järjestelin ja suodatin UNIX-komentorivityökalujen (sort ja unique) avulla tiedoston sellaiseen muotoon, jossa riveillä on kirjailijan nimi, kustantaja ja kyseisen kustantajan kautta julkaistujen teosten lukumäärä. Nyt data oli sellaisessa muodossa, että käytettävissäni oli kaikki ne tiedot, jotka oletin tarvitsevani mielessäni olevan grafiikan toteuttamiseksi koneen avulla.
Datasta syntyi kaavio Python-ohjelmointikielen NetworkX verkostoanalyysipaketin sekä Graphviz -visualisointityökalun suosiollisella avustuksella.
Python-skriptin nielemä tieto näytti tältä:
4 WSOY Töyrylä, Timo
19 WSOY Vaara, Elina
4 WSOY Vala, Katri
5 WSOY Venho, Johanna
...ja skriptin tuottama, DOT-muotoinen tieto kutakuinkin tältä:
"Vaara, Elina" [style=filled, fixedsize=true, height="0.25", width="0.25", shape=circle, role=author, fontsize=1, label="", color=lightgray];
WSOY [width="2.5", style=filled, fontsize=12, fixedsize=true, role=publisher, color=red, height="2.5"];
"Vaara, Elina" -> WSOY [color=gray37, penwidth=4];
Loppu olikin silkkaa automagiaa suurimmaksi osaksi. Latasin DOT-tiedoston Graphviz-ohjelmaan, joka pienen asetustensäätelyn jälkeen lykkäsi ulos haluamani grafiikan. Jahka saan opeteltua Graphviziä lisää, koitan josko saisin mankeloitua esityksen hieman havainnollisempaan muotoon.
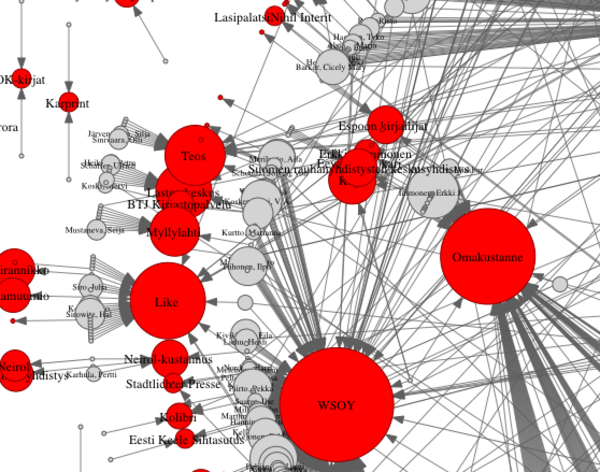
Kuvassa punaiset ympyrät ovat kustantajia ja harmaat kirjailijoita. Ympyrän koko heijastelee julkaistujen teosten määriä.
Esikatselukuva sisältää vain pienen osan koko grafiikasta -- ohessa kuva kokonaisuudessaan PDF-muodossa.